
Nodejs中的事件循环机制理解
为什么
最近在看Node.js,看到了 事件循环机制 的内容,有点难理解,遂写下这个文章
我之前学的是java,一般来说后端处理多线程任务的时候,就是开启多个线程或者进程嘛;但在Nodejs中靠的是事件循环机制。
Use one 线程 处理大批量的网络请求。
听起来匪夷所思,所以接下来就是这个机制的详解。帮助我理解这个循环机制
可以说,事件循环是 Node.js 最核心、最基础的机制之一,掌握它就等于掌握了 Node.js 异步模型的底层运行原理。
我如何看待事件循环
作为一名习惯于 Java 和 Spring 生态系统的后端工程师
第一个需要突破的思维是:“我不用再为每个请求拉起一个线程” 在 Node.js 里,一切都奔着“一个线程搞定多数连接”的方向走。
在 Node.js 里,有两类任务:同步任务和异步任务。同步任务就是我平时写业务逻辑时那种“马上做完”的代码,比如变量赋值、函数调用、console.log()
但是 ,比如调用 fs.readFile()、启动一个定时器、或者发起数据库/网络请求时,这就成了异步任务:这时,不会让主线程停下来等结果返回,而是把任务“登记”一下,接着让主线程继续处理新的请求。
这就是所谓的 调用栈(Call Stack)+ 事件队列(Event Queue)+ 事件循环(Event Loop) 的模式:
同步代码进入调用栈,完成后出栈;
异步操作注册一个回调,然后放到事件队列中等待;
事件循环不断检查:如果调用栈空了,就去事件队列里取一个任务回来执行。
这么一来,多路 I/O 请求就不会把主线程堵死。作为后端工程师,这种方式让我意识到:不是线程越多越好,不是每个请求都新开一个线程,而是如何让线程空闲的时候干事情,就是效率的关键。
从阶段视角看事件循环的“来回巡视”
事件循环不是一次性“做完就结束”,而是 反复巡视(循环)的一套机制。可以把它看作一个专职“调度员”,负责按固定流程不断检查「有没有同步任务」「有没有异步回调」——然后把能够执行的回调安排上。
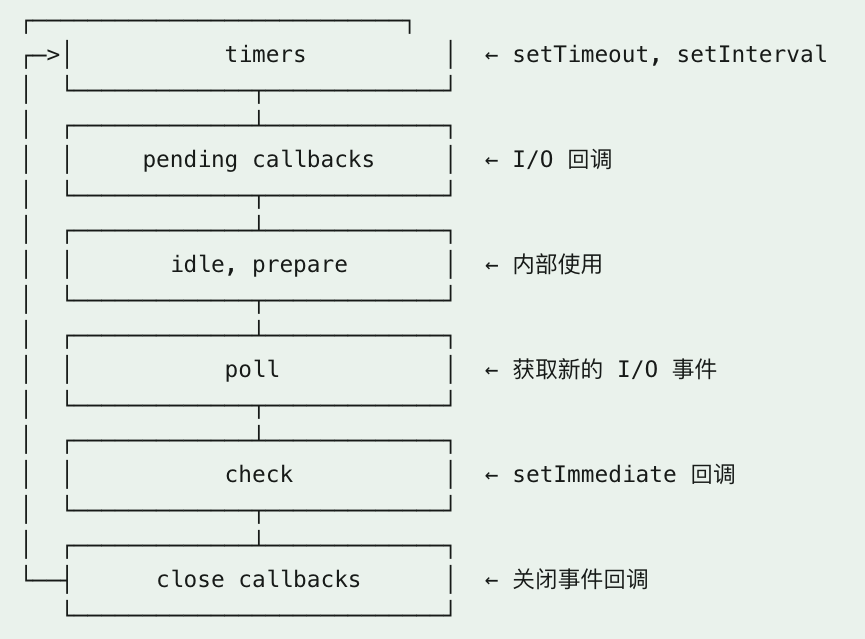
具体来说,这个调度员每一轮都会依次经过几个“阶段”——我理解成“巡视站点”——每个阶段都有自己的任务队列。例如:
Timers 阶段:检查所有由
setTimeout()/setInterval()注册、且“时间已到”的回调。I/O 回调阶段(Pending Callbacks):处理某些系统级 I/O 完成后延迟执行的回调。
Idle/Prepare 阶段:这是内部使用的准备阶段,平时我们业务代码不直接接触这个阶段,但它保障整个机制顺畅。
Poll 阶段:这个阶段非常关键,因为几乎所有 I/O 操作(如文件读写、网络请求)返回后,回调会在这里被拿出来执行。
Check 阶段:专门执行
setImmediate()注册的回调。Close 回调阶段:用于处理例如
socket.on('close')、流关闭等清理类回调。
每当一轮“巡视”结束,若有微任务(如 process.nextTick()、Promise .then)等待,则会在进入下一轮之前立即清理掉。
异步回调不是随机“某个时候”执行,而是在特定阶段、有规则地执行
微任务(Microtasks)与宏任务(Macrotasks)的优先级思考
微任务:在 Node.js 里,典型的微任务包括 process.nextTick、Promise .then / .catch 等。
宏任务:对应的就包括那些进入各阶段的回调,例如通过 setTimeout、setImmediate、I/O 回调等。
关键在于:每当某个阶段(如 timers、poll、check)执行完毕后,系统首先会清空微任务队列,然后再进入下一个阶段。这个“阶段->微任务清空->下阶段”流程
console.log('Start');
process.nextTick(() => console.log('nextTick'));
Promise.resolve().then(() => console.log('promise'));
setTimeout(() => console.log('timeout'), 0);
console.log('End');
Start
End
nextTick
promise
timeout
分析:
“Start” & “End” 属于同步代码,直接进调用栈执行。
接着
process.nextTick()是最优先的微任务,它会在当前阶段结束后马上执行。然后
Promise.resolve().then()属于微任务队列(但在nextTick之后执行)。接下来是
setTimeout(...,0)所注册的回调,这进入“Timers”阶段(下一轮事件循环)执行。最后是
setImmediate(),它执行在 “Check” 阶段,通常晚于 timers 阶段。
同步代码 → nextTick → Promise.then → 定时器(Timers)→ setImmediate
了解这个顺序后,调试异步代码时,我就能预测回调是什么时候跑,避免“为什么这行日志比那行早”的困惑。
局限性 & 实战提醒 — 我作为后端工程师的反思
虽然 Node.js 在处理高并发 I/O 场景时确实非常高效,但它并不是万能的。
CPU 密集型任务会阻塞事件循环:
如果我在 Node.js 主线程里执行一个耗时的计算(比如大规模递归、复杂算法、长时间循环等),整个事件循环就被卡住,其它异步 I/O 任务就会被拖延或无法响应。这就违背了 Node 本来 “非阻塞、高并发” 的初衷。
在这种场景下,正确的做法是尽量将 CPU 密集任务 “移出主线程”——例如使用 Worker Threads、子进程或拆分页段执行。不要忽略微任务/宏任务优先级陷阱:
我曾经因为没有注意到process.nextTick()与Promise.then()的优先级差异,而导致某条日志比预期早或晚输出。这在调试异步流程时非常坑。澄清:在某个阶段结束后,微任务会先执行,然后事件循环才切换到下一阶段。理解版本差异与实现复杂性:
虽然事件循环的 “六大阶段”模型(Timers → Pending Callbacks → Idle/Prepare → Poll → Check → Close Callbacks)是一个通用抽象,但具体到 libuv 版本、Node 版本、系统平台,细节会有差别。比如 Poll 阶段里的阻塞策略、定时器最低延迟、setImmediate()的行为等。参考官方文档说明:在 Poll 阶段若队列为空,则会转至 Check 阶段执行setImmediate()回调。日常实战建议:
避免在入口模块(如 app 启动时)执行过多同步初始化逻辑,以免阻塞第一轮事件循环。
对于 I/O 密集但逻辑简单的流程,Node 非常适合;而对于 CPU 密集(例如图像处理、大数据运算),应考虑将其交给专门线程或服务。
在写异步流程时,先思考 “这个回调是在什么时候执行” — 是同步结束立即、是微任务、还是下一轮循环的 Timers/Check 阶段。
在日志、监控、性能排查中,若发现响应延迟,优先排查是否主线程被同步任务阻塞、或微任务堆积。

